A informação da quantidade de habitantes dos municípios brasileiros é um dos dados basilares de diversos estudos. Por exemplo, combinando com outros dados quantitativos dos municípios é possível utilizá-los para calcular indicadores per capita, tais como o PIB per capita, a taxa de homicídios por 100 mil habitantes, a taxa de analfabetismo, entre outros. Assim, é importante ter esses dados disponíveis para análises.
Neste texto eu mostro como baixar esses dados de três bases do IBGE: os Censos Demográficos (1970 a 2022), as Contagens da População (1996, 2007) e as Estimativas da População (2001 a 2021); e consolidá-las em uma única base.
APIs do IBGE
Primeiro vamos entender como acessar os dados do IBGE. O IBGE disponibiliza uma API para acessar os dados do SIDRA, que é o sistema de recuperação de dados do IBGE. O SIDRA disponibiliza dados de diversas pesquisas em tabelas prontas para consulta. Cada tabela possui um código para referencia-la. Por sua vez, cada tabela possui diversos parâmetros que podem ser utilizados para filtrar os dados, como o período, o nível territorial, as variáveis, as classificações e as categorias.
A documentação da API do SIDRA pode ser acessada no link abaixo:
Além do SIDRA, o IBGE disponibiliza uma API de Agregados, que que fornece os metadados das tabelas do SIDRA. Os metadados disponíveis são os períodos, as variáveis, as classificações e as categorias – que são os parâmetros que podem ser utilizados para filtrar os dados numa consulta à API do SIDRA.
Cada tabela no SIDRA corresponde a um agregado na API de Agregados.
A documentação da API de Agregados do IBGE pode ser acessada no link abaixo:
Para acessar os dados do SIDRA, é necessário passar os parâmetros para a API.
Podemos passar os seguintes parâmetros para a API:
- código da tabela
- nível territorial & unidades territoriais
- variáveis
- classificações e categorias
Tabelas SIDRA
Censos (1970, 1980, 1991, 2000, 2010 e 2022)
A tabela 200 do SIDRA contém a população dos municípios do Brasil nos anos dos Censos, ou seja, 1970, 1980, 1991, 2000 e 2010. O censo de 2022 ainda não foi incluído nessa tabela. Para baixar a população de 2022, é necessário baixar a tabela 9514, que apresenta a população dos municípios do Brasil em 2022.
Contagens de população (1996 e 2007)
As contagens de população do IBGE, realizadas no meio da década, são disponibilizadas nas tabelas 305 e 793 do SIDRA. Essas contagens tem o objetivo de atualizar as estimativas de população entre os Censos1.
Estimativas da população (EstimaPop)
As estimativas de população do IBGE são disponibilizadas na tabela 6579 do SIDRA. Essas estimativas fornecem estimativas do total da população dos municípios do Brasil, com data de referência de 1º de julho de cada ano2.
O código
Primeiro vamos importar as bibliotecas necessárias.
from pathlib import Path
import requests
import sidrapy
Agora vamos definir as funções que vão baixar as tabelas do SIDRA.
A função get_periodos é utilizada para obter os períodos disponíveis de uma tabela. Ela utiliza a API de Agregados do IBGE.
def get_periodos(agregado: str):
url = f"https://servicodados.ibge.gov.br/api/v3/agregados/{agregado}/periodos"
response = requests.get(url)
return response.json()
A função download_table é utilizada para baixar uma tabela do SIDRA. Ela utiliza a biblioteca sidrapy para baixar a tabela. Essa função baixa a tabela e salva a tabela em formato CSV no diretório passado no argumento data_dir.
def download_table(
sidra_tabela: str,
territorial_level: str,
ibge_territorial_code: str,
variable: str = "allxp",
classifications: dict = None,
data_dir: Path = Path("data"),
) -> list[Path]:
"""Download a SIDRA table in CSV format on temp_dir()
Args:
sidra_tabela (str): SIDRA table code
territorial_level (str): territorial level code
ibge_territorial_code (str): IBGE territorial code
variable (str, optional): variable code. Defaults to None.
classifications (dict, optional): classifications and categories codes.
Defaults to None.
Returns:
list[Path]: list of downloaded files
"""
filepaths = []
periodos = get_periodos(sidra_tabela)
for periodo in periodos:
filename = f"{periodo['id']}.csv"
dest_filepath = data_dir / filename
dest_filepath.parent.mkdir(exist_ok=True, parents=True)
if dest_filepath.exists():
print("File already exists:", dest_filepath)
continue
print("Downloading", filename)
df = sidrapy.get_table(
table_code=sidra_tabela, # Tabela SIDRA
territorial_level=territorial_level, # Nível de Municípios
ibge_territorial_code=ibge_territorial_code, # Territórios
period=periodo["id"], # Período
variable=variable, # Variáveis
classifications=classifications,
)
df.to_csv(dest_filepath, index=False, encoding="utf-8")
filepaths.append(dest_filepath)
return filepaths
Agora vamos baixar as tabelas. Mas primeiro vamos criar um diretório para salvar os arquivos.
data_dir = Path("data")
data_dir.mkdir(parents=True, exist_ok=True)
Vamos criar uma lista no Python para colocar os caminhos dos arquivos baixados.
files = []
Agora vamos baixar as tabelas. Primeiro vamos baixar as tabelas de população dos Censos contida na tabela 200 do SIDRA.
Essa tabela contém a população dos municípios do Brasil nos anos dos Censos, ou seja, 1970, 1980, 1991, 2000 e 2010. O censo de 2022 ainda não foi incluído nessa tabela. Para baixar a população de 2022, é necessário baixar a tabela 9514, que apresenta a população dos municípios do Brasil em 2022.
# Populacao Censos
sidra_tabela = "200"
territorial_level = "6"
ibge_territorial_code = "all"
files_census = download_table(
sidra_tabela=sidra_tabela,
territorial_level=territorial_level,
ibge_territorial_code=ibge_territorial_code,
variable="allxp",
classifications={"2": "0", "1": "0", "58": "0"},
data_dir=data_dir,
)
files.extend(files_census)
Agora vamos baixar a tabela de população do Censo de 2022.
# Populacao Censo 2022
sidra_tabela = "9514"
territorial_level = "6"
ibge_territorial_code = "all"
files_census_2022 = download_table(
sidra_tabela=sidra_tabela,
territorial_level=territorial_level,
ibge_territorial_code=ibge_territorial_code,
variable="allxp",
classifications={"2": "6794", "287": "100362", "286": "113635"},
data_dir=data_dir,
)
files.extend(files_census_2022)
Agora vamos baixar as tabelas de população das Contagens contidas nas tabelas 305 e 793 do SIDRA.
# Populacao Contagens
sidra_tabelas = (
"305",
"793",
)
for sidra_tabela in sidra_tabelas:
files_counts = download_table(
sidra_tabela=sidra_tabela,
territorial_level=territorial_level,
ibge_territorial_code=ibge_territorial_code,
data_dir=data_dir,
)
files.extend(files_counts)
Por fim, vamos baixar as tabelas de população das Estimativas contidas na tabela 6579 do SIDRA.
# Populacao Estimativas
sidra_tabela = "6579"
files_estimates = download_table(
sidra_tabela=sidra_tabela,
territorial_level=territorial_level,
ibge_territorial_code=ibge_territorial_code,
data_dir=data_dir,
)
files.extend(files_estimates)
Consolidando os arquivos
Agora vamos consolidar os arquivos baixados em um único arquivo.
Primeiro vamos importar a biblioteca pandas e definir as funções de leitura dos arquivos CSV e refinamento dos dados.
import pandas as pd
def read_file(filepath: Path, **read_csv_args) -> pd.DataFrame:
print("Reading file", filepath)
data = pd.read_csv(filepath, skiprows=1, na_values=["...", "-"], **read_csv_args)
data = data.dropna(subset="Valor")
return data
def refine(df: pd.DataFrame) -> pd.DataFrame:
df = (
df.dropna(subset="Valor")
.rename(
columns={
"Ano": "ano",
"Município (Código)": "id_municipio",
"Valor": "pessoas",
}
)
.assign(pessoas=lambda x: x["pessoas"].astype(int))
)
df[["nome_municipio", "sigla_uf"]] = df["Município"].str.split(" - ", expand=True)
df = df.drop(columns="Município")
df = df[["ano", "id_municipio", "nome_municipio", "sigla_uf", "pessoas"]]
return df
Com a biblioteca pandas importada e as funções necessárias definidas, podemos executar o código a seguir, que lê os arquivos baixados, refina os dados e salva em um arquivo CSV único.
df = refine(
pd.concat(
(
read_file(file, usecols=("Ano", "Município (Código)", "Município", "Valor"))
for file in files
),
ignore_index=True,
)
)
A função read_file é utilizada para ler os arquivos baixados. Nessa função, os valores ... e - são considerados como valores nulos. E as linhas com valores nulos são removidas. Nós pulamos a primeira linha, pois ela contém o código das colunas, não o nome das colunas. Passamos o argumento usecols para ler apenas as colunas que nos interessam (Ano, Município (Código) e Valor).
O método pd.concat é utilizado para concatenar os DataFrames. No código acima eu uso uma expressão de geradores3 para ler os arquivos baixados e concatená-los em um único DataFrame.
A função refine é utilizada para renomear as colunas e remover linhas com valores nulos.
Podemos visualizar as primeiras linhas do DataFrame utilizando o método head.
print(df.head())
ano id_municipio nome_municipio sigla_uf pessoas
0 1970 1100106 Guajará-Mirim RO 27016
1 1970 1100205 Porto Velho RO 84048
2 1970 1200104 Brasiléia AC 12311
3 1970 1200203 Cruzeiro do Sul AC 43584
4 1970 1200302 Feijó AC 15768
Podemos visualizar informações sobre o DataFrame utilizando o método info.
print(df.info())
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 145380 entries, 0 to 145379
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 ano 145380 non-null int64
1 id_municipio 145380 non-null int64
2 nome_municipio 145380 non-null object
3 sigla_uf 145380 non-null object
4 pessoas 145380 non-null int64
dtypes: int64(3), object(2)
memory usage: 5.5+ MB
None
Por fim, podemos salvar os dados em um arquivo CSV utilizando o método to_csv.
df.to_csv("populacao_municipios.csv", index=False, encoding="utf-8")
Pronto! Agora temos um arquivo CSV com a população dos municípios do Brasil.
Gráfico
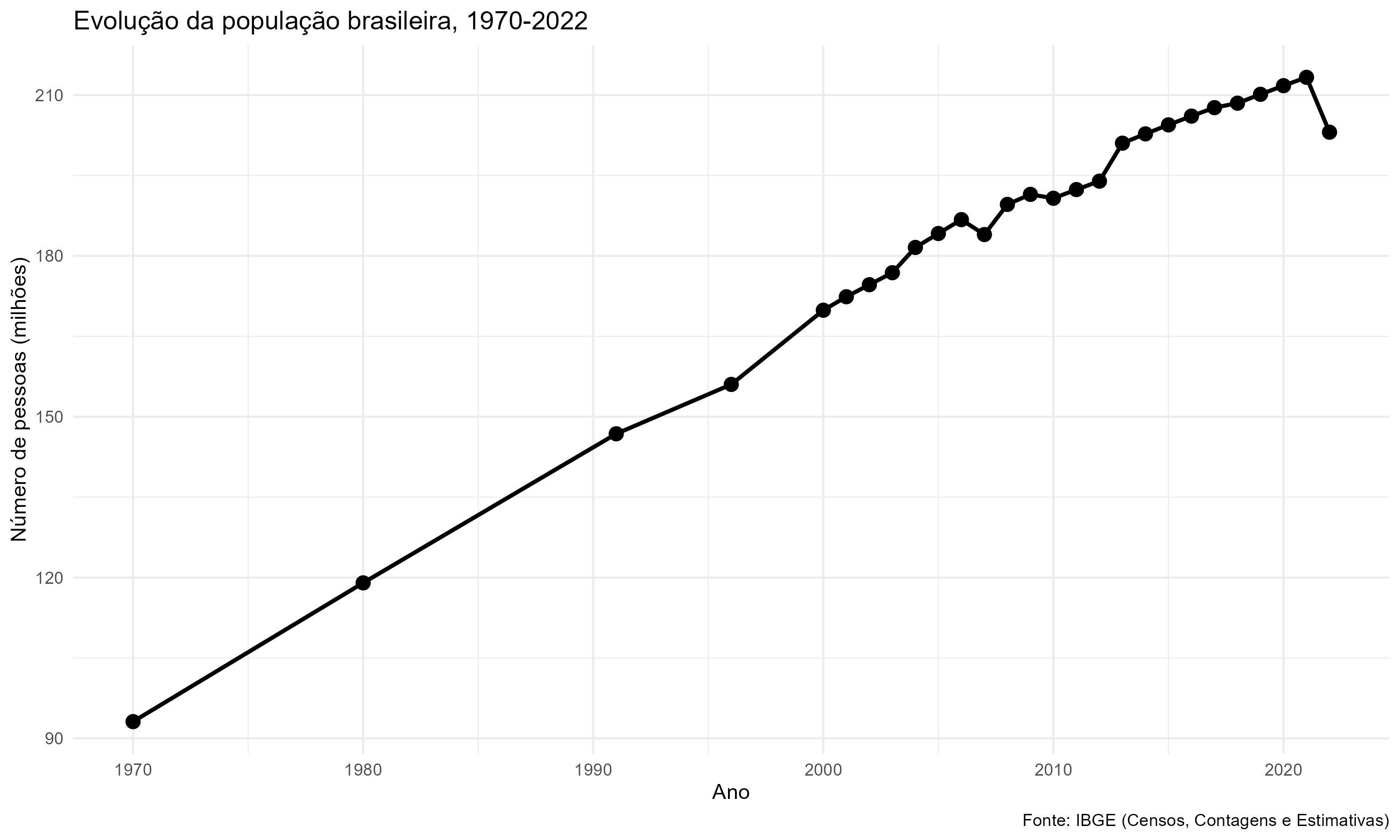
Por fim, a titulo de exemplo, vamos plotar um gráfico com a evolução da população brasileira de 1970 a 2022 (nesse trecho eu utilizo a biblioteca tidyverse do R, mas você pode utilizar a biblioteca matplotlib do Python para plotar o gráfico).
library(tidyverse)
dados <- read_csv("data/populacao_municipios.csv")
dados |>
group_by(ano) |>
summarise(n_pessoas = sum(n_pessoas)) |>
ggplot(aes(x = ano, y = n_pessoas / 1000000)) +
geom_line(linewidth = 1) +
geom_point(size = 3) +
labs(title = "Evolução da população brasileira, 1970-2022",
x = "Ano",
y = "Número de pessoas (milhões)",
caption = "Fonte: IBGE (Censos, Contagens e Estimativas)") +
scale_y_continuous(labels = scales::comma) +
theme_minimal()
Conclusão
Don’t repeat yourself! Automatize!
Neste texto eu mostrei como baixar os dados de população dos municípios do Brasil do IBGE. Esses dados são muito importantes para diversos estudos e análises, e agora você pode baixá-los e consolidá-los em um único arquivo.
Coloquei o arquivo CSV gerado no Kaggle, você pode baixá-lo nesse endereço https://www.kaggle.com/datasets/danielkomesu/population-of-brazilian-municipalities.